导读:在大模型浪潮席卷全球的当下,数据与智能的深度融合正在重塑企业的核心竞争力,#DeepSeek 等大模型技术及应用的爆发式发展,使得数据不再仅是静态资源,而是驱动业务实时决策,赋能模型精准进化的核心原料。本次分享将深入剖析 DeepSeek 时代所需要的数据引擎。
01 DeepSeek 带来的变革
1. 大模型的 Aha Moment
在人工智能技术快速发展的背景下,DeepSeek 的出现引发了行业内的广泛关注与深刻变革。它不仅为用户带来了新的交互体验,更在技术、商业和数据生态等层面产生了深远影响。
从商业角度来看,DeepSeek 最显著的特征是其低廉的成本。一方面,通过技术创新实现了硬件成本的降低;另一方面,采用开源模式,不依靠垄断来获取高额利润。开源意味着技术和代码开放共享,众多开发者可以参与优化和改进,减少了中间环节和垄断溢价,进而使得基于该技术所提供的服务成本降低,价格亲民。因而,成为行业内的“价格屠夫”。
其 R1 模型更是在学术界及产业界引发强烈反响。DeepSeek 能引爆业界,迎来其 Aha Moment,主要原因在于 DeepSeek 是目前国内能轻松访问的最领先的 AI 模型。以前只有国外的 OpenAI 具有类似能力,但其屏蔽中国大陆访问,而 DeepSeek 则将先进技术完整呈现给大家。
目前,已有很多公共服务集成了 DeepSeek 模型。最早的 DeepSeek 曾因使用人数激增而出现服务挤爆的情况。为满足更多用户的需求,越来越多第三方平台开始接入 DeepSeek 模型,为用户提供了多样化的使用渠道,例如硅基流动、纳米 AI、腾讯元宝、MiniMax、火山方舟等。此外,一些领域服务,如车载智能系统“理想同学”、手机端的“VIVO 蓝心大模型”等,也已完成 DeepSeek 的接入,进一步拓宽了用户的访问渠道。
DeepSeek 的 V3 模型价格便宜,而思维链模型 R1 价格相对较高。在其 API 平台上,V3 模型和R1 模型差异计费,R1 模型能带来卓越的推理效果。
2. 开源
DeepSeek 等模型出现前,OpenAI 是被公认好用的模型,用户要么通过 Azure 接入 OpenAI,要么直接使用其服务,处于垄断状态。而 DeepSeek 大模型开源,带来了与以往不同的情况:一方面提供大规模且廉价的技术服务;另一方面,以往敏感领域因涉及数据需发送给外部服务,使用 OpenAI 存在安全合规问题,DeepSeek 开源后改变了这一局面 。
而 DeepSeek 开源后,私有化部署需求激增,DeepSeek 一体机应运而生,在离线、内网等受限环境中极具价值。适用于多种受限环境。同时,模型量化技术允许在硬件规格较低的设备上运行,虽性能有所折损,但仍能保留部分核心能力。
此外,DeepSeek还支持模型定制化。由于其开源特性,可通过“Fine-Tune”(指可以在特定任务上进行微调)方式对模型进行深度定制,不局限于提示词调整,还能直接向模型输入数据,使其更贴合业务模式需求。与仅使用提示词实现效果相比,两种方式在不同任务中各有优劣。
3. Data is Everything
DeepSeek 的出现还重塑了数据的核心地位。在传统互联网时代,数据孤岛现象普遍存在,各平台数据相对封闭。进入大模型时代,这种数据隔离反而创造了新的价值。以腾讯元宝为例,其联网搜索功能不仅涵盖互联网数据,还能调用微信公众号等私域数据,结合 DeepSeek 模型提供更具针对性的服务,在特定领域的搜索效果优于标准版 DeepSeek。小红书也基于 DeepSeek 开展 AI 服务内测,充分挖掘私域数据价值。由此可见,DeepSeek 的出现推动了数据与模型的深度融合,开启了数据驱动人工智能发展的新阶段。
02 PingCAP 基于 OpenAI 的 AI 产品发展历程
1. 早期实践
PingCAP 自 2023 年初起开展基于人工智能的实践探索,在数据库领域与 AI 技术融合方面取得了一系列成果。
在早期实践中,PingCAP 推出了 TiDB Cloud Chat2Query 功能,这是一种 SQL 智能助手(SQL Copilot),最早基于 OpenAI 的 GPT3 模型开发。该功能可根据用户在自有数据集上的自然语言查询需求,如针对 SP500 数据集,查询收入增长最高的前十家公司,根据你输入的自然语言自动分析并生成相应的 SQL 查询语句,确定查询的数据表,以及规划查询结果的展示方式。
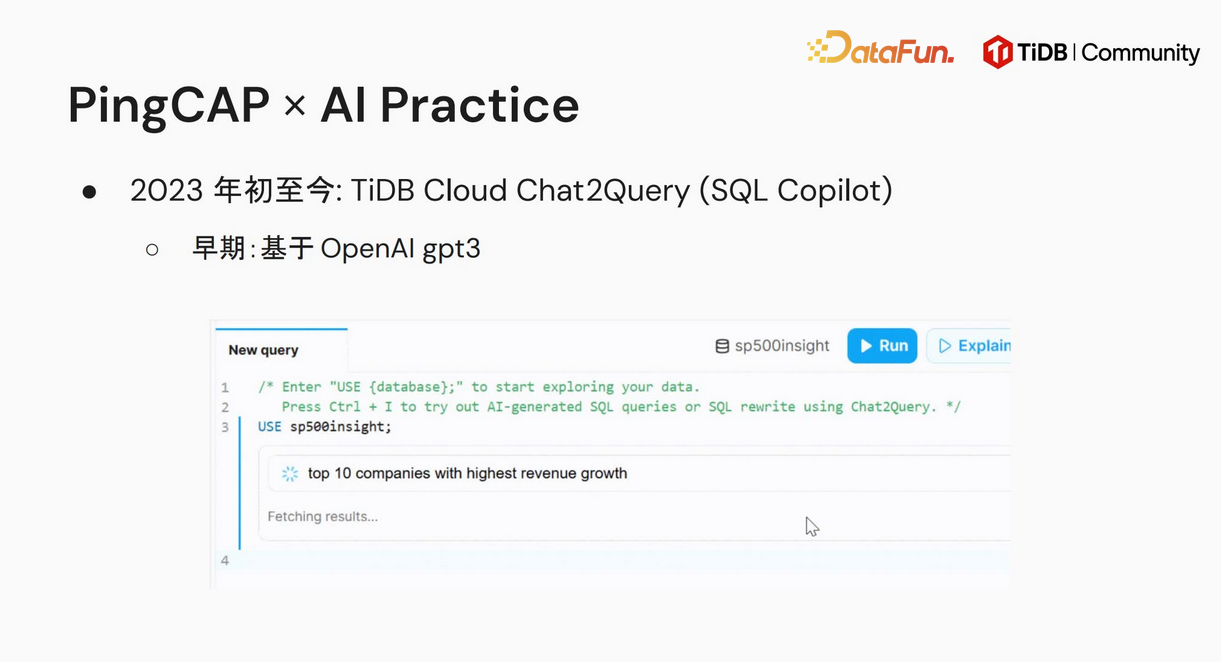
为提升 Chat2Query 功能的服务质量,PingCAP 采取了多种优化策略。一方面,随着 OpenAI 新模型的推出,通过替换为 GPT4 等更强性能的模型,直接提升服务效果。另一方面,在相同模型基础上,从多个技术方向深入研究:
提示工程优化:借鉴网络上优秀的提示优化案例,调整输入提示,为大模型提供更充分信息,使其更好地理解用户需求并完成任务。
补全领域知识(RAG):采用信息检索方式,将与用户提问相关的领域知识资料检索出来提供给大模型,辅助其决策。由于大模型输入窗口存在数据量限制,因此筛选相关度高的资料,以在有限输入内实现更好效果。
应用思维链技术:通过为大模型提供示例,如过往任务的处理方式,为其提供可遵循的任务执行路径,帮助大模型理解任务逻辑,显著提升生成内容的质量。简单版本的思维链可通过添加引导语句实现,复杂形式则借助多样化示例引导。
实施多步迭代策略:利用大模型的热度参数特性,由于大模型单次生成内容可能存在错误或质量不佳的情况,在 SQL 应用场景中,通过多次生成 SQL 语句并执行验证,直至得到正确可用的 SQL。除此以外,在其他一些场景也采用这种多步验证的方式,如 SWE-bench(用于评估大模型代码编程能力的基准测试)中,让大模型生成多个代码片段,再由其他模型或算法从多个结果中筛选出最优结果,从而提升最终输出质量。
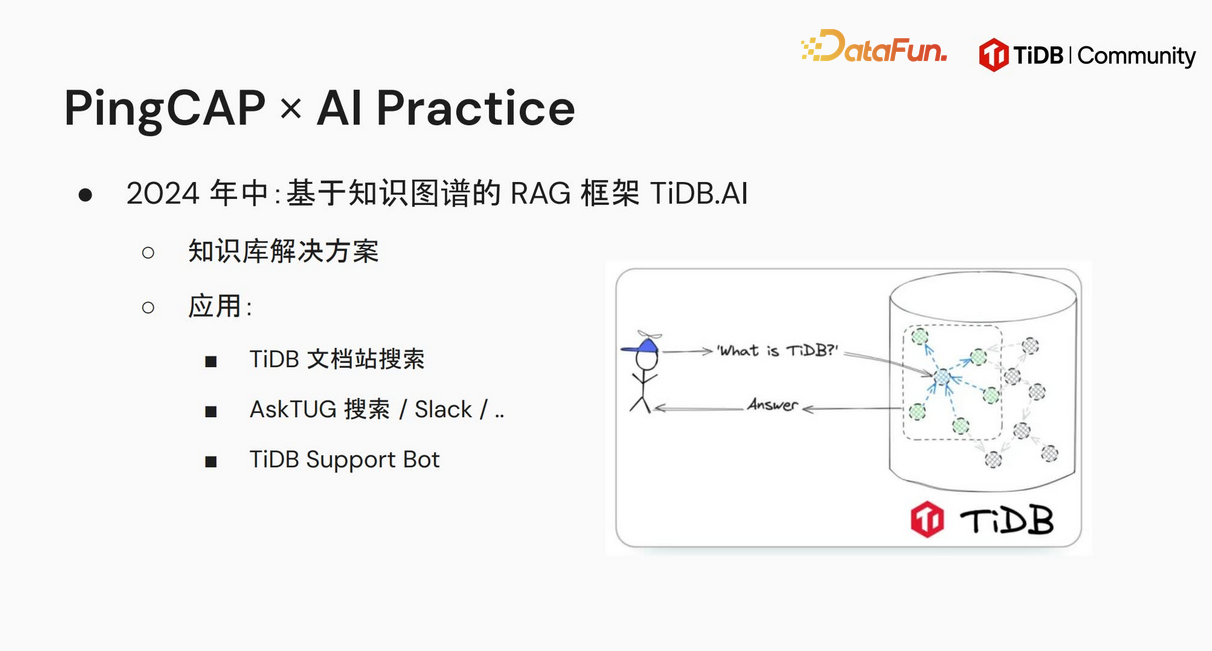
2. 基于知识图谱的 RAG 框架 TiDB.AI
到 2024 年中,PingCAP 进一步开发了基于知识图谱的 RAG 检索框架 TiDB.AI。该框架应用于多个场景,包括 TiDB 文档站搜索、AskTUG 搜索以及 IM 频道(如 Slack)提问等,能够自动识别用户问题,并从相关知识库中检索匹配内容,为用户提供准确的问题解答和信息支持。
3. AutoFlow 框架
2024 年底将相关技术进化成了 AutoFlow 框架。因 TiDB.AI 本身基于知识图谱,所以对公共内容进行了抽象,使其成为基础构建模块,更好地支撑更多业务。AutoFlow 框架可通过 Pip 安装,且能基于该框架构建任何知识图谱应用。
AutoFlow 框架的质量提升同样也经历了漫长的演进过程。除了升级更强的模型之外,在 RAG 方向经历了如下演进历程。
(1)Vector RAG
早期的 RAG 是通过向量嵌入模型搜索相近片段来实现增强生成。当用户给出一个提问,会先通过 embedding 模型在整个知识库中搜索出语义相近的内容,召回的内容提供给大模型进行总结性回答。
(2)Graph RAG
基于知识图谱进一步强化知识召回的效果。这种方式弥补了 Vector RAG 在处理非公共领域知识和复杂关系时的不足。
召回包括关键字召回、向量召回等方式。关键字召回是召回相似文本内容,例如输入 Macbook Pro,关键字召回会将其与 Macbook 进行关联。向量召回,则是召回语义相近的内容。例如“鱼”和“水生动物”,在文字上并不相近,但语义上存在相似性,所以也会被关联在一起。
而知识图谱可以进一步补充领域相关知识,建立实体间的关系连接。例如,谷歌和微软在文本关键字层面可能无直接关联,但在知识图谱中,基于同属美国公司、互联网公司、在纳斯达克上市等关系建立了强关联。
(3)RAG Workflow 编排
传统 RAG 工作流多采用静态编排方式,要求大模型按预设顺序执行任务,例如先对用户提问进行 refine,再搜索相关内容,最后将搜索到的内容提供给大模型,由大模型进行总结。然而,实际用户问题复杂多样,简单问题可能通过一轮搜索就能得出优质答案,复杂问题则需要多轮数据召回和策略调整。RAG Workflow 编排基于学术界改进思路并落地实现,建立了动态可调整的编排机制。该机制能够根据问题的复杂程度灵活调整工作流程,如对于简单问题采用简洁高效的流程,对于复杂问题通过编辑流程,增加知识搜索步骤、优化知识整合方式等,以实现更好的回答效果。这种动态编排极大地提升了 RAG 系统的适应性和灵活性,相比固定流程,在处理不同类型问题时展现出更高的效率和质量 。
(4)RAG + FineTune(WIP)
RAG 和 FineTune 在 RAG 技术体系中虽各有特点,但结合使用是未来重要发展方向。FineTune 通过训练过程将先验知识融入模型,有助于提升模型对特定领域知识的理解和应用能力,但难以实时纳入最新知识。而 RAG 能够针对新数据进行持续召回,实现新数据的实时利用。同时,大模型存在幻觉问题,需要对输出内容进行信息来源追踪,RAG 能够满足这一需求,而FineTune则无法做到;另一方面,RAG 存在上下文长度限制,FineTune 可在一定程度上解决该问题。目前,RAG + FineTune 的结合仍在探索完善阶段,未来需根据不同应用场景和需求,深入研究两者的融合策略,充分发挥各自优势,实现 RAG 系统性能和回答质量的进一步提升 。
4. 统一数据基座
在传统的数据基座架构中,针对不同召回方式,通常会适配不同类型的数据库,例如关系型数据库、向量数据库和图数据库等。
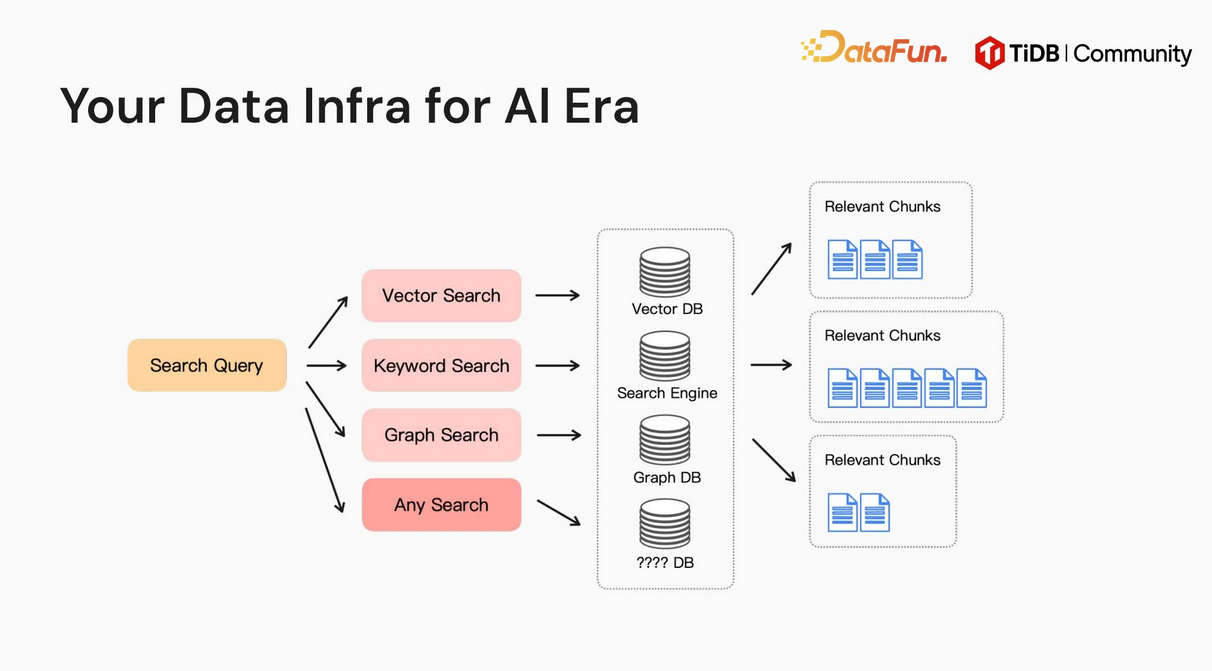
TiDB 通过统一数据库架构,取代了传统架构中多类型数据库并存的模式,将所有功能集成于一身。只需维护单个 TiDB 数据库,即可同时支撑关键字检索、向量检索、图检索等多种能力,甚至能够兼容未来新增的召回方式,真正实现“One Database for All”的极简高效数据管理目标。

03 TiDB 场景功能及未来展望
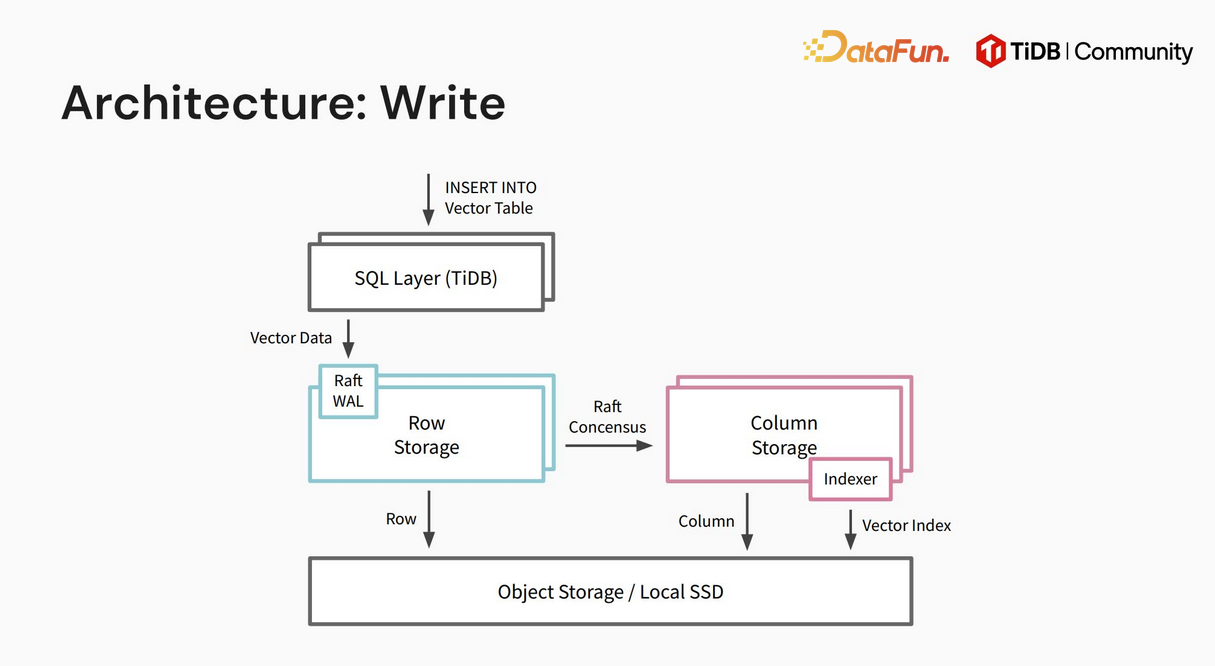
1. 如何实现向量召回
TiDB 数据库同时支持行存和列存,向量作为一种数据类型,在行存和列存模式下均可处理。此外,向量索引仅存在于列存模式中。在进行搜索时,优化器会依据实际情况,智能判断选择行存、列存或两者结合的方式,以最适宜的存储模式进行数据检索,实现向量召回。
2. TiDB 在 AI 生态中的作用
TiDB 面向 RAG 演进数据库内核,目前已提供大规模向量检索,9.0 LTS 版本将提供关键字检索功能,还会跟进混合 Ranking、自动向量嵌入、图搜索加速等实践,助力应用高效优质开发。
除了内核演进之外,也在针对 AI 重塑数据库功能,使数据库更加智能。例如:
基于 LLM 知识,实现全文搜索多语种识别和分词。传统中文搜索依赖分词效果,因内置词典或算法问题效果不理想,大模型在分词上优势大,可重塑数据库全文搜索等功能提升性能。
在数据库迁移场景中,大模型可用于对 SQL 进行改写和创作,改变以往依赖人工的方式。并且,大模型能够自动验证 SQL 语句执行是否成功,以及对比执行前后原始数据和新数据是否存在差异,实现数据库迁移过程中的自动化操作。
辅助运维,包括提供索引建议(index advisor)、异常检测、容量预测等功能,帮助提升数据库运维的效率和准确性。
数据库的“AI 运维”很像“自动驾驶”和“自动编程”的故事。尽管大模型在数据库领域能够发挥重要作用,例如解放重复性工作、加速数据处理并辅助决策,但数据库作为关键的基础设施,在现阶段仍需要人的决策和执行,大模型尚无法直接替代数据库管理员(DBA)的工作。
以上就是本次分享的内容,谢谢大家。
04 问答环节
Q1:不同领域的知识图谱构建代价大,需很强的行业专家经验,有什么快速构建和对齐的思路?如何借助大模型来做?
A1:在 AutoFlow 中,知识图谱由大模型自动构建,基于 DSP UI 框架。首先会由大模型处理一遍信息,输出信息之间的关系。虽自动构建可能有不准确之处,但知识图谱是可编辑的,所以可以人工做进一步修正。
Q2:针对用户提问的实体信息与数据库中的 value 值不匹配的情况该如何处理?
A2:若用户提问信息并非直接以文本匹配方式在数据库中存在,可采用向量搜索,通过语义相近方式召回语义相近的内容。在 AutoFlow 中,向量搜索、关键字搜索、知识图谱搜索会同时进行,将三路搜索召回的相关片段一起提供给大模型做综合决策。
Q3:向量生成时还需要切分内容吗?
A3:若有一篇很长的文章,第一步是切分 chunk,切分完后生成对应的向量。理论上可只把切分后的向量存在数据库里,不存内容原文,用户提问时可通过其他方式找回 chunk。实际情况中,如使用 TiDB,向量内容和 chunk 内容可存在同一张表的同一行里,召回时可同时得到向量和原文,使开发更简便。
Q4:Chat2Query 或 NL2SQL 中会面临跨库跨表业务,除了尽可能补充语义描述库表信息外,还有什么方式或者经验能够覆盖到大部分客户的查询诉求?现在效果差就去调用流程,做起来比较费时。
A4:除库表信息外,还会给到一些 feature 的 example。将 description 以及它们之间的 relationship 等原始信息都给到大模型,还包括 domain knowledge(如 TiDB 自己的专门语法等),在提示词上对大模型进行优化。领域模型通过 RAG 方式做召回,feature 的 example 形成思维链让大模型一步一步思考。最后自动做反复验证,看 SQL 是否正确。TiDB 官网博客有相关内容的详细介绍。
Q5:Chat2Query 主要针对 OLTP 场景,那如果针对 OLAP 这种没有强依赖关系的情况,是否有实现可能或解决思路?另外,自动提升 SQL 性能、自动改写 SQL 等场景如何实现?
A5:在提升 SQL 性能方面,我们尝试了通过大模型自动为已写的复杂 AP 查询做性能优化,但不是简单地让大模型优化就能做到,而是需告诉大模型常见的优化方式,也是类似于 RAG 的方式。
关于 OLAP 的问题,目前大模型难以生成非常复杂的 SQL 语句,所以复杂 OLAP 执行失败率较高。可通过多步生成缓解这一问题,即让大模型先对用户问题做拆解,分析出需要的数据,再针对每部分数据执行一次 SQL 迭代,类似于 Agent 模式,虽不能直接生成单个 OLAP SQL 语句,但从结果上能达到用户以自然语言想要了解数据的结果。


